


大數據覆蓋的技術點有很多,其中spark框架就是其中一種,本期小編為大家介紹的大數據培訓教程就是關于Spark框架中RDD和DataFrame的區別是什么?RDD(提供了一種高度受限的共享內存模型;DataFrame是一種分布式的數據集,并且以列的方式組合的。在spark中RDD、DataFrame是最常用的數據類型,在使用的過程中你知道兩者的區別和各自的優勢嗎?關于如何具體的應用今天就好好的分析一下。
大數據之Spark框架中RDD和DataFrame的區別:
一、RDD、DataFrame分別是什么?
1、什么是RDD?
RDD(Resilient Distributed Datasets)提供了一種高度受限的共享內存模型。即RDD是只讀的記錄分區的集合,只能通過在其他RDD執行確定的轉換操作(如map、join和group by)而創建,然而這些限制使得實現容錯的開銷很低。RDD仍然足以表示很多類型的計算,包括MapReduce和專用的迭代編程模型(如Pregel)等。
2、什么是DataFrame?
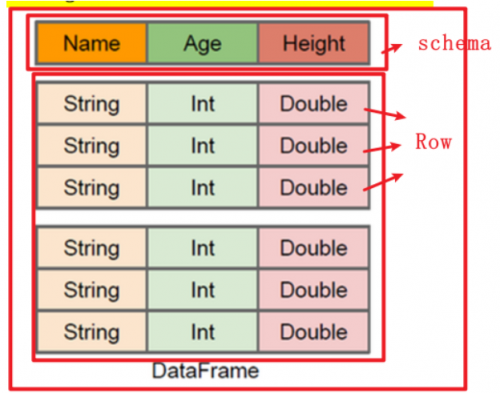
DataFrame是一種分布式的數據集,并且以列的方式組合的。類似于關系型數據庫中的表。可以說是一個具有良好優化技術的關系表。DataFrame背后的思想是允許處理大量結構化數據。提供了一些抽象的操作,如select、filter、aggregation、plot。DataFrame包含帶schema的行。schema是數據結構的說明。相當于具有schema的RDD。
二、RDD、DataFrame有什么特性?
在Apache Spark 里面DF 優于RDD,但也包含了RDD的特性。RDD和DataFrame的共同特征是不可性、內存運行、彈性、分布式計算能力。
它允許用戶將結構強加到分布式數據集合上。因此提供了更高層次的抽象。我們可以從不同的數據源構建DataFrame。例如結構化數據文件、Hive中的表、外部數據庫或現有的RDDs。DataFrame的應用程序編程接口(api)可以在各種語言中使用,包括Python、Scala、Java和R。
1、RDD五大特性:
1.(必須的)可分區的: 每一個分區對應就是一個Task線程。
2.(必須的)計算函數(對每個分區進行計算操作)。
3.(必須的)存在依賴關系。
4.(可選的)對于key-value數據存在分區計算函數。
5.(可選的)移動數據不如移動計算(將計算程序運行在離數據越近越好)。
2、DataFrame特性:
1.支持從KB到PB級的數據量
2.支持多種數據格式和多種存儲系統
3.通過Catalyst優化器進行先進的優化生成代碼
4.通過Spark無縫集成主流大數據工具與基礎設施
5.API支持Python、Java、Scala和R語言
三、RDD與DataFrame的區別
RDD是彈性分布式數據集,數據集的概念比較強一點。容器可以裝任意類型的可序列化元素(支持泛型)RDD的缺點是無從知道每個元素的【內部字段】信息。意思是下圖不知道Person對象的姓名、年齡等。

DataFrame也是彈性分布式數據集,但是本質上是一個分布式數據表,因此稱為分布式表更準確。DataFrame每個元素不是泛型對象,而是Row對象。
DataFrame的缺點是Spark SQL DataFrame API 不支持編譯時類型安全,因此,如果結構未知,則不能操作數據;同時,一旦將域對象轉換為Data frame ,則域對象不能重構。
DataFrame=RDD-【泛型】+schema+方便的SQL操作+【catalyst】優化
DataFrame本質上是一個【分布式數據表】
DataFrame優于RDD,因為它提供了內存管理和優化的執行計劃。總結為以下兩點:
a.自定義內存管理:當數據以二進制格式存儲在堆外內存時,會節省大量內存。除此之外,沒有垃圾回收(GC)開銷。還避免了昂貴的Java序列化。因為數據是以二進制格式存儲的,并且內存的schema是已知的。
b.優化執行計劃:這也稱為查詢優化器。可以為查詢的執行創建一個優化的執行計劃。優化執行計劃完成后最終將在RDD上運行執行。
如果您想了解更多關于千鋒教育或者大數據培訓教程,可以咨詢我們的客服小姐姐,他們會為您做詳細的解答。









 京公網安備
11010802035719號
京公網安備
11010802035719號